이번 프로젝트는 Audio 편집기이다.
그러나 나는 디지털 오디오에 대해 매우 아는 바가 없기 때문에, 좀 공부를 한 뒤에 프로젝트를 진행하려고 한다.
하다못해 mp3 도 잘 안 듣는데다 eq한번 건드려 본 적 없는데 뭘 알겠어... 설마 그걸 내가 직접 짤 날이 올줄은 몰랐지.
일단 최소한의 튜토리얼을 위해, 강의를 보면서 공부하고 기록을 남겨 두기로 했다.
처음에는 수기로 작성하였는데 내 필기 솜씨가 개판인데다 내가 필기로 남겨놓은 자료를 다음에 읽어 본 기억이 없다.
그리고 분명 잃어버릴 것이다.
그렇기에 아예 블로그에 남겨두려고 한다. 대단한 지식은 아니더라도 남겨두어서 나쁠 일은 없을 테니까.
강의를 들으면서 필기하고 그 뒤에 블로그에 옮겨적는 중.
정확히는 강의를 필기한 다음에 내가 이해한 걸 기반으로 정리하고 의역하고 있다. 좋게 말하자면 주석을 붙이는 중이다.
그리고 그러다 보니 잘못 이해한 경우 원본과 다른 헛소리일 수도 있다...ㅋㅋㅋㅋ
강의는 유료 강의를 보고 있다.
코드는 오픈소스로 뿌렸는데 코드 사용법이 유료라니 허허;
https://app.pluralsight.com/library/courses/digital-audio-fundamentals/table-of-contents
일부 사진을 캡쳐해서 올릴건데 강의 전체도 아니고 스크린샷 정도는 저작권에 문제가 안 되겠지? 그렇다고 믿고 싶다.
어차피 내 블로그가 뭐 대기업도 아니고 걸리기야 하겠냐만...
Sampling
디지털 오디오는 아날로그(자연 소리)를 그대로 표현할 수 없다. 이진화되어 표현되어야만 한다.
그래서 사용하는 방식이 바로 sampling 이다.

위 사진처럼 실제 파형의 일부만을 뽑아서 저장하는 거고, 이걸 sampling 이라고 한다.
sampling에서는 아래 세 가지가 가장 중요하다.
1. Sample Rate
2. Bit Depth
3. Channel
아는 것도 모르는 것도 있지만 다 정리해 두자.
Sample Rate
1초간의 소리에서 1000개의 sample 을 뽑아냈다면 1000Hz, 1KHz 라고 한다.
자주 사용되는 sample rate는 다음과 같다.
44.1khz : CD 등의 음악
96khz : 전문 스튜디오에서 녹음한 고품질 음악
8, 16khz : 통화
이 sample rate는 사운드카드에 따라 지원하는 범위가 제한되어 있다. 일부 사운드카드는 96khz를 지원하지 않을 수도 있다는 뜻이다.
또한 사운드카드는 하나의 sample rate로 작동하는데, 즉 동시에 다른 sample rate를 지닌 여러 음원을 재생할 수 없다는 의미이다. 그럴 경우 높은 쪽은 sample rate로 resampling 을 거져 재생된다고 한다.
sample rate가 높으면 무작정 좋아진다고 생각할 수 있지만, 인간이 들을 수 있는 한계는 보통 44.1khz로 거의 다 표현된다. 그리고 sample rate가 올라간다는 것은 sample의 수가 늘어난다는 뜻이고, 당연히 용량이 증가한다.
용량이 증가하면 하드 용량, 메모리 용량, 네트워크 용량 등 다양한 페널티가 가해지기에 최소한일수록 좋은 것이다. 사람의 목소리는 8khz면 거의 표현 가능하고, 전화는 품질보다 속도가 중요하기에 8,16khz를 사용하는 것이다.
스펙트럼 분석기를 통하여 소리를 틀어보면 낮은 음계의 소리일수록 저주파 쪽에 에너지가 실린다.


위 사진에서 보다 낮은 음을 실행 시 에너지가 낮은 쪽에 몰리는 걸 볼 수 있다. 즉 우리가 생각하기에 느껴지는 '높은 소리' 가 실제로도 주파수가 높은 대역이라는 것만 알아두자.
그러면 sample rate는 어떻게 결정해야 할까?
일단 사람의 가청주파수는 20hz~20khz 정도라고 한다. 물론 나이나 개인차 등에 따라 다르겠지만 보통 저렇다고 한다.
Nyquist-shannon Sampling Theorem 에 따르면, sample rate는 표현하고자 하는 최고 주파수 *2 로 충분하다고 한다.
즉 사람의 가청 주파수 최대값인 20khz까지 표현하고 싶다면 sampling rate가 40khz면 된다는 뜻이다. 그래서 일반 cd는 44.1khz인 것이다. 44.1khz면 인간이 들을 수 있는 대부분의 소리를 표현할 수 있다.
그 이유는 어딘가 논문에 있겠지만 거기까진 내 범위 밖이라고 생각해서 굳이 찾아보지 않겠다.
덤으로 사람의 목소리는 최대 4khz라서 통화가 8khz인 거라고 한다.
Aliasing
Sample rate 가 원본 신호에 포함된 고주파수를 sampling하기엔 너무 낮을 때 발생하는 문제를 말한다.

위 사진에서 보면, 붉은 점의 샘플만 보고 음을 내면 원본과 어마어마한 차이를 낳는다는 걸 쉽게 알 수 있다.
이런 문제가 바로 Aliasing이다.
이 문제를 해결하기 위해서 사용되는 것이 low pass filter 라는 것이다.
단순하게 설명하자면 입력 신호에서 원치 않는 고주파를 제거하여 표현하기 어려운 값을 샘플링하기 전에 지워내는 것이다. 보통 사운드카드 혹은 오디오 API가 알아서 수행한다고 한다.
low pass filter를 사용하게 되면 위에서부터(고주파부터) 잘려나가므로, 심벌즈 등의 높은 소리부터 사라지게 된다. 낮은 소리는 남아있는다.
filter를 조절하여 얼마나 잘라낼지를 조절하는 걸 들어보면 마치 멀리서 들리는, 혹은 벽 너머로 들리는 것처럼 점점 소리가 둔탁해지는 걸 느낄 수 있다.
Bit Depth
각 샘플을 저장하는 데 몇 비트를 사용할 것인가.
아래는 주로 사용되는 메이저한 bit depth 이다.
8bit sample
256 가지 진폭을 표현 가능하다. 256개로도 왠만큼은 소리를 표현가능하다.
다만 signal-to-noise raito가 나쁜 편이다. 이 말이 무슨 뜻인가 하면, 전체 소리에서 잡음이 많이 낀다는 뜻이다.
실제로 8bit sampel을 들어보면 치지직 거리는 잡음이 많이 끼는 것을 느낄 수 있다.
16bit sample
CD, MP3 등에서 사용되는 메이저한 포맷이다. singed 2 bit integer (short) 사이즈로 저장된다.
노이즈가 적어(good singnal-to-noise ratio) 듣기에 편안한 소리를 낸다.
이는 dynamic range가 크기 때문인데, dynamic range란 가장 작은 소리와 가장 큰 소리 사이의 차이(데시벨) 로 16bit 의 경우 96db이다.
24bit sample
dynamic range는 144db이다. 이 범위는 인간의 가청주파수는 커녕 고막과 스피커가 감당할 수 있는 범위조차 벗어나므로 큰 의미는 없다.
사용되는 이유는 headroom 을 늘리기 위해서이다. 다르게 표현하면 clipping을 피하기 위해서.
진폭의 최대값이 표현 가능한 범위를 벗어날 경우, max값에 걸려서 높은 부분이 평평해지고 소리가 왜곡되는데 이를 clipping 이라고 한다.

당연히 이는 좋지 않으므로, 가장 높은 주파수와 허용하는 max값 사이에 여유가 있는 것이 좋다. 그래야 진폭을 키울 일이 있을 때 문제가 생기지 않는다.
이런 여유공간을 headroom 이라고 하며, headroom을 확보하기 위해서 24bit sample이 사용된다.
32bit sample
일단, 32bit 마이크 따위는 지구상에 없다. 강의 기준(약 10년 전...)으로는 21bit를 넘는 마이크는 존재하지 않는다고 한다.
그러니 24bit 이상은 필요 없는데, 이게 왜 있냐 하면 프로그래머를 위해서이다.
프로그래머라면 알겠지만 32bit, int 는 가장 쓰기 편한 단위이다. 24bit 정수형 따위는 존재하지 않는다. (어딘가 있을지도 모르지만 사용하기는 쉽지 않을 것이다)
그렇기에 프로그래밍적인 편의를 위해서, 32bit 공간에 24bit 정보를 담아 사용하는 것이 32bit sample 이다. 용량은 낭비되더라도 동적인 사용은 오히려 빠를수 있다고 보인다. 일종의 4byte padding 같은 거라고 보면 될 것 같다.
floating point sample
32bit (single), 64bit (double) 두 가지가 존재. 소리 표현은 single로 충분하지만 레코딩 프로그램에서는 내부적으로 double을 쓴다고 한다.
DSP(Digital signal processing)시에 편의를 위해서 사용된다. 정수로 샘플링된 파일 또한 연산시에는 1.0f~-1.0f 로 정규화되어 사용한다. 정수보다는 소수 쪽이 연산하기에 편하다는 건 반론의 여지가 없으니까.
연산이 종료되었을 때 정규화 범위에서 벗어나는 경우 clipping 한 뒤에 정수 sample로 돌려보낸다.
Decibels (데시벨)
소리의 단위로서 자주 사용되는 단위이다.
흔히 몇 데시벨 소리 처럼 사용하지만 실제로는 절대값이 아닌 상대값이다. 일반적으로 말하는 데시벨 수치는 사람의 목소리를 기준점으로 잡은 것으로, 50db 정도가 듣기 편안한 소리라고 한다. 자세한 정보가 필요하면 찾아보자.
0db는 동일한 음압, +3db면 약간 큰 소리, -3db면 약간 작은 소리 등이다.
진폭이 절반이 되면 -6db, 두 배가 되면 +6db이다.
디지털 오디오에서는 (Digital Audio Level) 보통 표현 가능한 최대값(full scale, 16bit의 경우 65535, 2^16)이 0db로 표현된다고 한다.
데시벨 계산식은 다음과 같다.
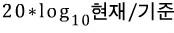
여기서 현재가 기준의 절반일 경우, 20 * log{10}(1/2) 이므로 -6db가 되는 것이다.
dynamic range를 계산하는 방법은 현재를 max, 기준을 1로 잡는 것이다. 16bit의 경우 20*log{10}(65535) = 96db 이다.
Channel
이건 다행이도(?) 나도 잘 아는 개념이다.
하나의 마이크로 녹음하여 양쪽 스피커(이어폰)에서 같은 소리가 나는 것을 mono(1ch), 두개의 마이크로 녹음하여 양쪽 스피커에서 다른 소리가 나는 것을 stereo(2ch) 라고 한다.
즉 하나의 마이크, 하나의 스피커가 각각 하나의 채널이 된다.
흔히 말하는 5채널 사운드 영화 같은 건 스피커가 5개인 거고, 녹음할 때 5개의 마이크를 쓴 거다. (5ch)
다만 이 채널은 사운드카드에 따라 지원하는 수가 다른데, 일반 사운드카드는 스테레오만 지원하지만 고급 사운드카드의 경우 8, 16개도 지원한다고 한다.
input channel (마이크) 와 output channel (스피커) 가 따로 있다.
'개발언어 > NAudio' 카테고리의 다른 글
| [Digital Audio] 3. Audio Effect (0) | 2021.07.08 |
|---|---|
| [Digital Audio] 2. Audio File Format (0) | 2021.07.08 |
| [NAudio] 반복재생하기 (0) | 2021.07.08 |
| [NAudio] 재생 속도 조절 (0) | 2021.07.08 |
| [NAudio] Spectrogram 그리기 (0) | 2021.07.08 |



